Control numerical precision level#
Note
The Cerebras cluster currently supports only training with mixed precision data types. Ensure your models have float16 or bfloat16 inputs and float32 arithmetic operations. When combined with Train with dynamic loss scaling, mixed precision can result in speedups in training. With bfloat16 training precision, dynamic loss scaling is not required.
Overview#
You can control the level of numerical precision used for training runs for large NLP models. This may be referred to as “precision optimization level” (POL) in other documentation.
Setting the numerical precision#
Set the precision_opt_level flag in the .yaml configuration for all models included in Cerebras Model Zoo. The precision_opt_level flag can be found in the runconfig section:
runconfig:
precision_opt_level:
...
The precision_opt_level functionality reflects a tradeoff between model precision and performance depending on the numerical setting. For this release:
precision_opt_level: 0makes use of single-precision (float32) accumulations to ensure higher precision.precision_opt_level: 1is an optimal tradeoff between precision and performance and usesfloat32reductions in attention and a combination offloat32andbfloat16/float16reductions in matrix multiplication for improved performance.precision_opt_level: 2is a high-performance setting and utilizes combination offloat32andbfloat16/float16reductions in attention and matrix multiplication kernels, andbfloat16/float16softmax in attention for best performance.
By default, Cerebras Model Zoo models have precision_opt_level: 1 with bfloat16, which provides convergence and matches the numerical results of other accelerators.
Note
Cerebras trained models, such as Cerebras-GPT have been trained using
precision_opt_level: 0. This setting is recommended to get the best model when the parameters are more than 6.7B.
precision_opt_level: 2 is used as a Cerebras internal tool to evaluate the future performance of the hardware.
The CS system supports the following data formats:
32-bit floating-point format:
IEEE single-precision (binary32), also known as FP32
16-bit floating-point format:
IEEE half-precision (binary16), also known as FP1
BFloat16 has eight exponent bits and is designed for deep-learning applications
The 16-bit arithmetic uses 16-bit words and is always aligned to a 16-bit boundary.
The single-precision arithmetic uses even-aligned register pairs for register operands and 32-bit aligned addresses for memory operands.
Note
Memory is 16-bit word addressable. It is not byte addressable.
Numerical precisions#
FP32 Single-Precision#
The FP32 is equivalent to IEEE binary32 (single-precision), with 8-bit exponent and 23-bit explicit mantissa.
Sign: 1 |
Exponent: 8 |
Mantissa: 23 |
FP16#
The FP16 implementation follows the IEEE standard for binary16 (half-precision), with 5-bit exponent and a 10-bit explicit mantissa.
Sign: 1 |
Exponent: 5 |
Mantissa: 10 |
BFloat16 half precision#
This section contains an explanation of bfloat16-dtype that is enabled in PyTorch for GPT-2, GPT-3, GPT-J, and GPT-neox models as part of the automatic mixed precision mode.
Automatic mixed precision is a mode that allows training deep learning models with a mix of single precision floating point float32 and half precision floating points such as float16 or bfloat16.
The benefits of the mixed precision mode are primary lying in performance. It is an optimization technique that allows you to train your networks faster, but without loss in quality. This phenomenon is due to the fact that some layers of the neural networks can be executed without high precision level, such as convolutional or linear layers. They’ve proven to be much faster when executed with float16 or bfloat16. However, other operations, such as reductions, often require a higher precision level in order to maintain the same quality results.
This trade-off of what needs to be casted to half dtype and what should be maintained in a single precision is included in the recipe of “automatic mixed precision algorithm“. In a nutshell, this recipe measures the performance of the network in default precision, then walks through adding castings to run the same network with a mixed precision setting to optimize performance without hurting accuracy.
Mixed precision does not require you to specify bfloat16 as a half precision floating point; however, it has shown some benefits over applying float16. Below we are going to discuss bfloat16 in more granular details.
BFloat16 Floating Type#
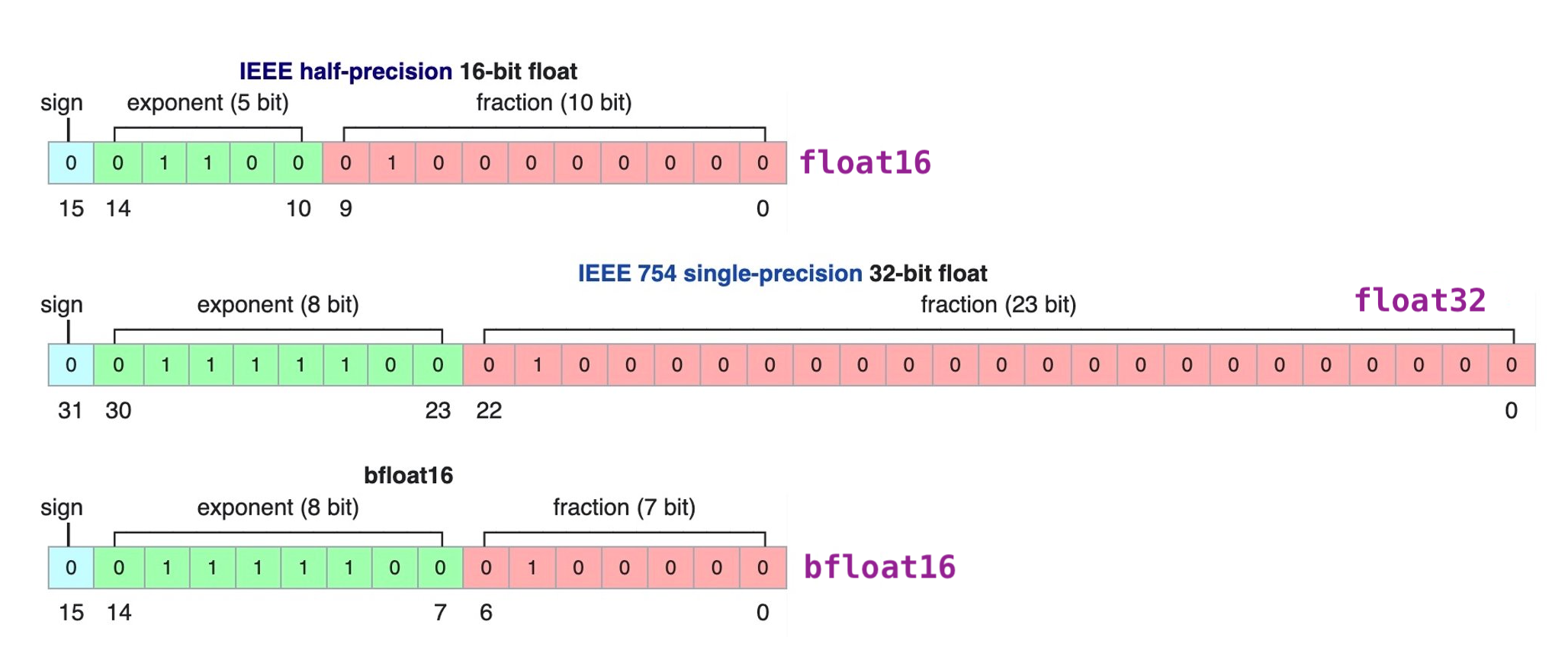
bfloat16 is a custom 16-bit floating point format for deep learning that’s comprised of one sign bit, eight exponent bits, and seven mantissa bits. This is different from the industry-standard IEEE 16-bit floating point, which was not designed with deep learning applications in mind. The figure below demonstrates the internals of three floating point formats: (a) float16: IEEE half-precision, (b) float32: IEEE single-precision, and (c) bfloat16.
We can see that bfloat16 has a greater dynamic range (number of exponent bits) than float16, which is identical to float32.
Experiments: Automatic Mixed Precision and BFloat16#
We experimented with a large amount of deep learning networks, and comparing between bfloat16 and float16 modes, we can see that bfloat16 is 18% faster, significantly less prone to the weight grow and shows better eval scores.
Our experiments demonstrated that choosing bfloat16 is beneficial over pure float32 or a mixed version with float16. It improves efficiency of the training, saves space while maintaining the same accuracy level. This happens due to the fact that deep learning models in general are more sensitive to changes in exponent rather than mantissa.
Training behavior with the bfloat16 setting is more robust and is less prone to having various underflows, overflows, or any other numerical instability during training similarly to training with pure float32 dtype. This is happening because exponent size of bfloat16 floating point is the same as float32.
How to Enable BFloat16#
To enable bfloat16 in the mixed precision mode, allow the next changes in the config file:
model:
use_bfloat16: True
mixed_precision: True
As you can see in addition to changes specific to mixed precision and bfloat16 parameter, we need to disable loss scaling. As we described above, bfloat16 has the same exponent size as float32, thus it will have identical behavioral for underflows, overflows, or any other numeric instability during training. Originally, loss scaling factor was introduced for the mixed precision mode with float16 setting. It was necessary to scale the loss to avoid these side effects. bfloat16 does not require loss scaling, thus comes close to being a drop-in replacement for float32 when training and running deep neural networks.
To try out some of our networks with this setting, refer to gpt2, gpt3, and gptj references.