Overview#
The Cerebras Wafer-Scale cluster is designed to train neural networks with near-perfect linear scaling across millions of cores without the inconvenience of distributed computing. The following list describes the cluster’s components:
One or more CS-2 systems, powered by the Wafer-Scale Engine (WSE). The CS-2s run the core training and inference computations within a neural network. Each rack-mounted CS-2 contains one WSE. The system powers, cools, and delivers data to the WSE. For more information, visit WSE-2 datasheet, virtual tour of the CS-2, and the CS-2 white paper
MemoryX technology is used to store and intelligently stream a model’s weights to the CS-2 systems
SwarmX technology integrates multiple CS-2s into one Cerebras cluster to work together for training a single model. SwarmX broadcasts weights (from MemoryX to the cluster) and reduces (sums) gradients (in the other direction)
Input preprocessing servers provide the needed data preprocessing to training samples before they can be sent to the CS-2 systems for training, inference, and evaluation
Management servers orchestrate and schedule the resources of the Cerebras cluster
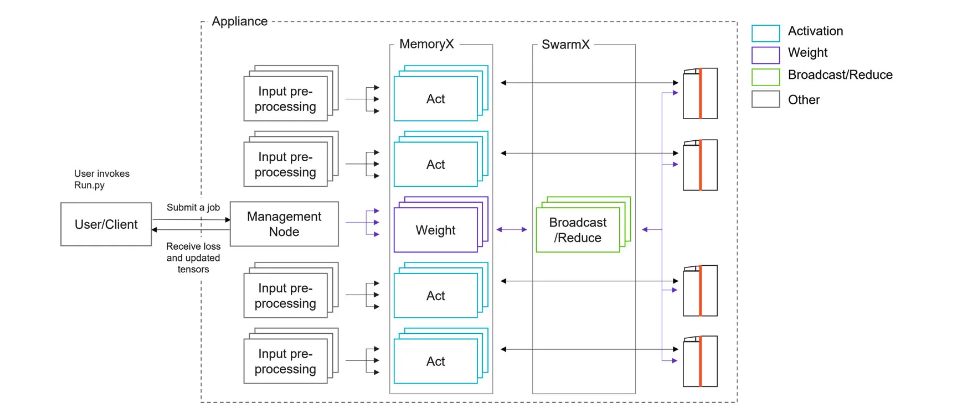
Fig. 1 Topology of Cerebras Wafer-Scale cluster#
Develop code and submit training/evaluation jobs from a user node. Note that the user node is a CPU node and is not part of the cluster that is connected to the Cerebras Cluster through the management server, as shown in Fig. 1. All scheduling of resources is done in the management server. You, therefore, only need to specify how many CS-2 systems you want to use for training or evaluation.
Important
For documentation related to the installation and administration of the Cerebras Wafer-Scale Cluster, visit Cerebras deployment documentation.