Cluster monitoring with Grafana#
Overview#
A Grafana dashboard lets you visualize, query, and explore your system’s metrics and enables you to access your system logs and traces. Cerebras offers you two Cerebras-tailored Grafana Dashboards: Cluster Management Dashboard and WsJob Dashboard.
Cluster Management Dashboard#
The Cluster Management Dashboard shows the overall state of the cluster. It includes the following:
CS-2 systems
Overall CS-2 systems status and errors
Nodes:
Kubernetes nodes warnings and errors
Space usage health
Network
Hardware NIC errors
Kubernetes CNIs errors
Cluster Management
Errors for Cerebras Cluster Management services
Kubernetes system services
Alerts
Current alerts on the cluster
The following figure displays Cerebras’s Cluster Management dashboard:

WsJob Dashboard#
The WsJob Dashboard displays job-related metrics and is useful when checking a job’s resource usage and any software or hardware errors relevant to this job.
There are five panes in this dashboard:
Job overviewDisplays the overview of memory/cpu/network bandwidth numbers for all replicas of selected job
Job associated software errorsDisplays job runtime errors (currently only shows
OOMKilledstatus)
Job associated hardware errorsDisplays any NIC, CS-2, or physical node that is assigned to this job and is having errors during the job execution
Replica viewDisplays memory/cpu/network bandwidth numbers for each
replica_idof thisreplica_typein each chart.Replica_typerepresents a type of service processes for a given job. It can be one of these types:weight,command,activation,broadcastreduce,chief,worker,coordinator.Replica_idcorresponds to the specific replica for a job and a replica type
Assigned nodesDisplays physical nodes status that are assigned to the chosen
replica_typeandreplica_id
MemX performanceShows iteration-based performance,
iteration time,cross-iteration time, andbackward iteration time
The following figure displays Cerebras’s WsJob dashboard:
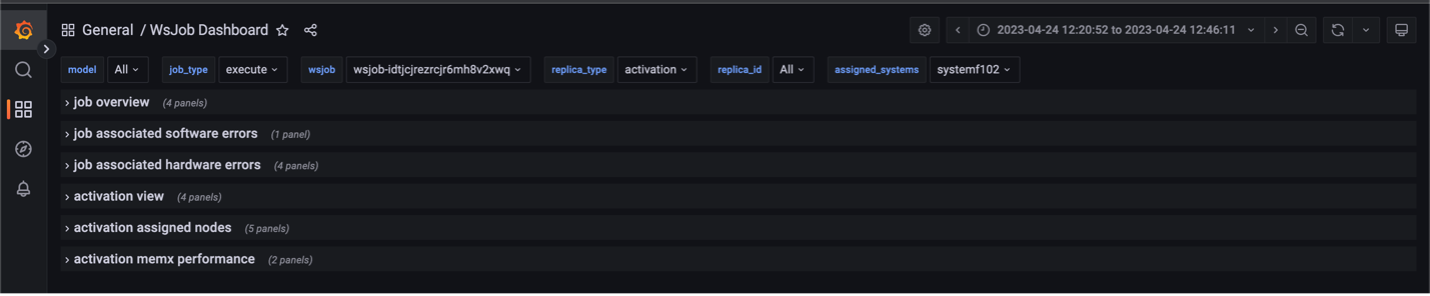
On the left you can find options to search for particular metrics and view metric details.
There are also filters for users to select:
wsjobIndicates the ID of the weight-streaming run, which is used to select between different runs on a particular system
replica_typeAllows selecting between the activation, weight, and all server metrics
assigned_systemsIndicates the system name being shown in the logs
Other fields available that are useful are the model, job_type, and the replica_id.
Prerequisites#
You have access to the user node in the Cerebras Wafer-Scale Cluster. Contact your sys admin if you face any issues in the system configuration.
You can run a port-forwarding SSH session through the user node from your machine with this command:
$ ssh -L 8443:grafana.<cluster-name>.<domain>.com:443 myUser@usernodeNote
This command uses the local port
8443to forward the traffic. You can choose any unoccupied port on your machine.
How to get access?#
Links are accessible from the General/Cerebras tab. The following figure displays a Cerebras dashboard:
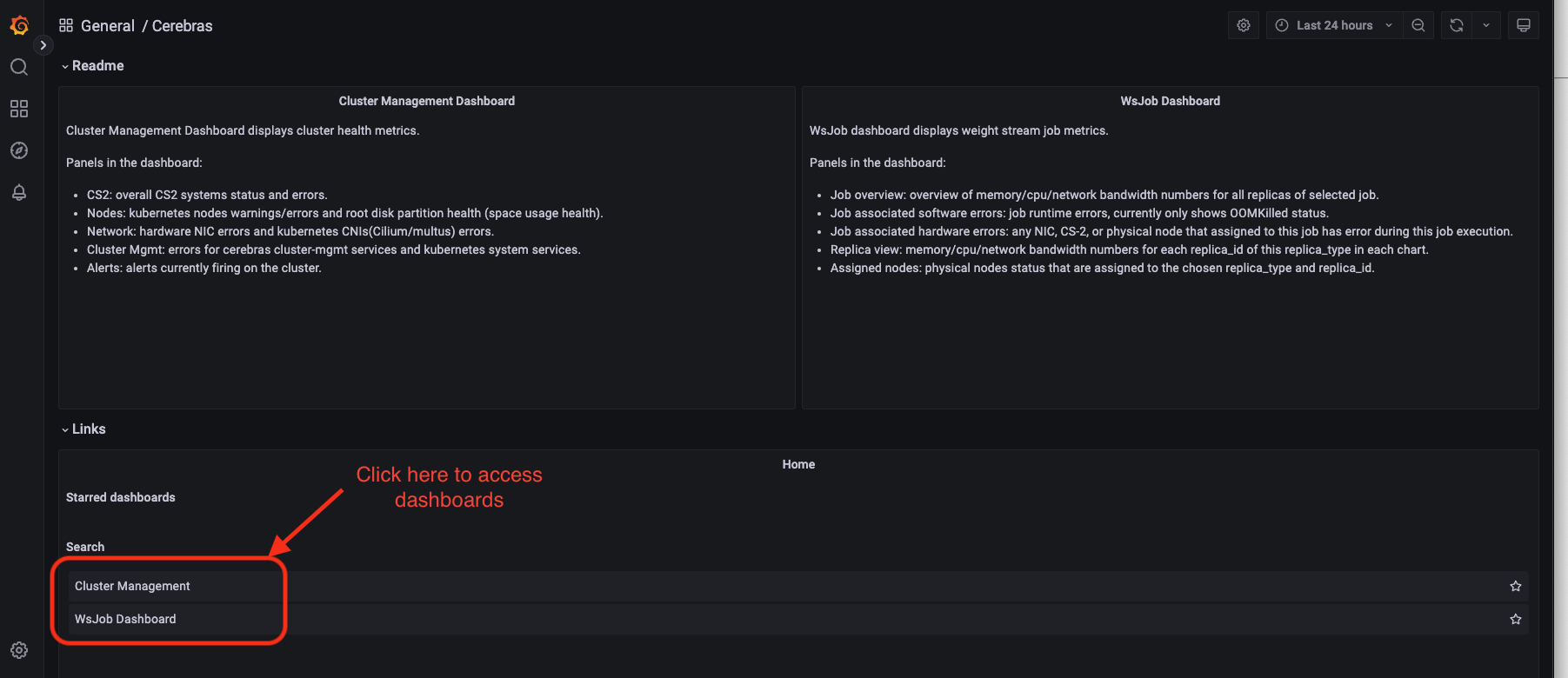
Steps to get access#
1. Ask your system admintrator to set up the Grafana database. URLs come in the format:
grafana.CLUSTER-NAME.DOMAIN.com For example: grafana.mb-systemf102.cerebras.com
2. Get authentication credentials for Grafana (username and password) from your system administrator.
3. Add the Grafana TLS certificate to your browser keychain. The grafana TLS certificate is located at /opt/cerebras/certs/grafana_tls.crt on the user node. This certificate is copied during user node installation process. Download this certificate to your local machine and add this certificate to your browser keychain.
On a Chrome browser on Mac OS:
Go to
Preferences->Privacy and Security->Security->Manage CertificatesAdd
grafana-tls.crtintoSystemkeychain certificates. Make sure to setAlways Trustwhen using this certificateNext, edit your local machine’s
/etc/hostsfile to point the IP of the user node to Grafana: <USERNODE_IP> grafana.<cluster-name>.<domain>.comFinally, navigate in your browser to the URL
HTTPS://grafana.<cluster-name>.<domain>.comto access the Grafana Dashboards
Viewing performance metrics using the WsJob dashboard#
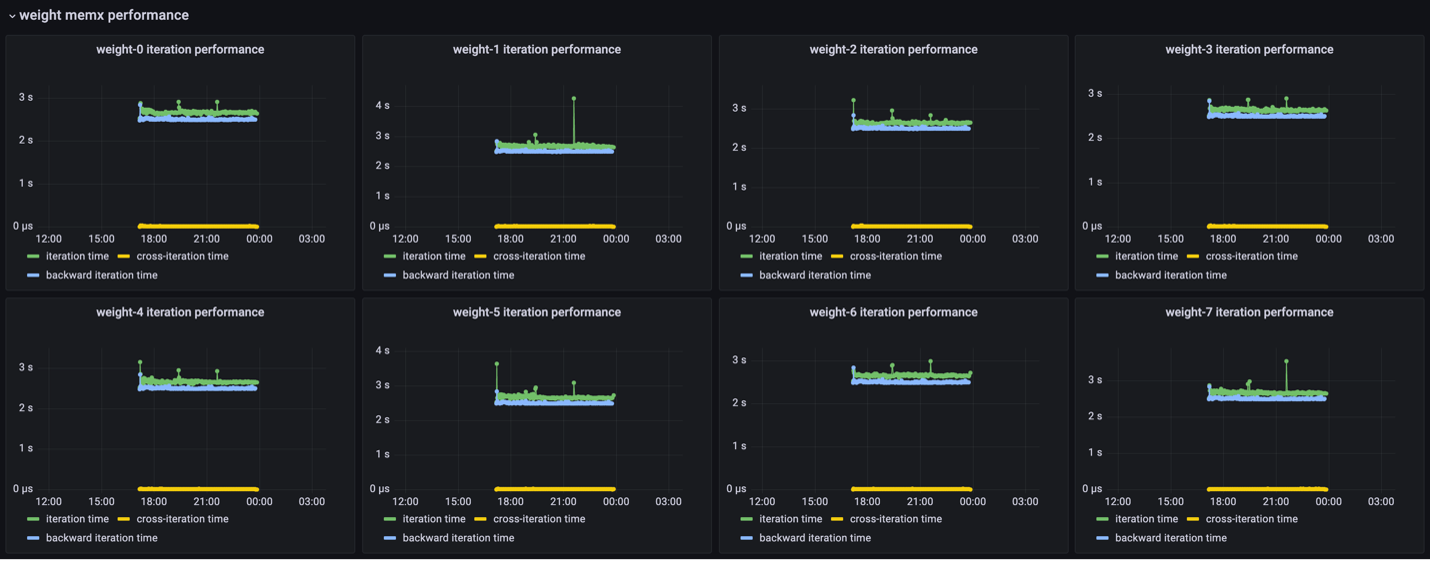
You can view cluster iteration-performance metrics by tracking update times across the weight servers.
Our current dashboard implementation shows iteration time, forward-iteration time, backward-iteration time, cross-iteration time, and input starvation.
Iteration timeIndicates the time from the end of iteration
i-1on the weight servers to the end of iterationion the weight servers.Forward-iteration timeIndicates the time spent in iteration
iduring the forward pass.Backward-iteration timeIndicates the time spent in iteration
iduring the backward pass.Cross-iteration timeIndicates the time between the last gradient receive of an iteration to the first weight send. A high value indicates an optimizer performance bottleneck.
Input starvationIndicates the time spent waiting on the framework to receive activations.
These statistics are shown in the following image and can be used to identify performance bottlenecks in the training process:
Viewing utilization metrics using the WsJob Dashboard#
The Replica view metric displays memory/cpu/network bandwidth numbers for each replica_id of this replica_type
in each chart. Replica_type represents a type of service process for a given job. It can be one of these
types: weight, command, activation, broadcastreduce, chief, worker, and coordinator.
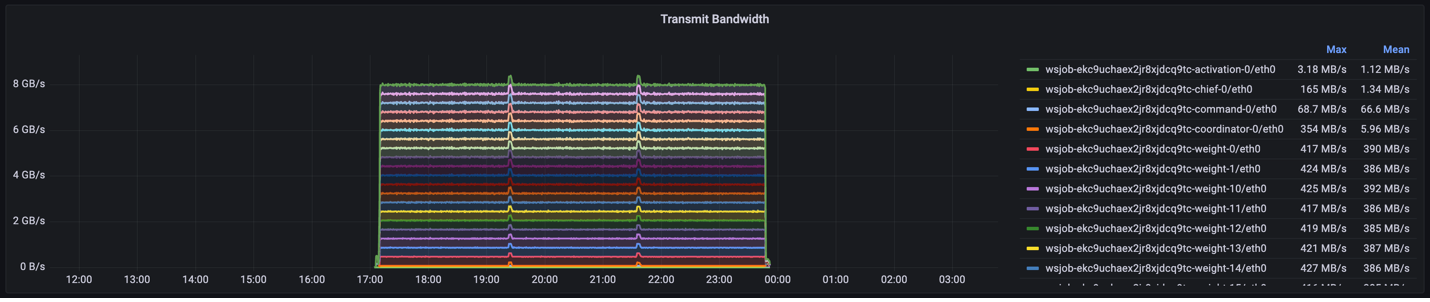
1. Transmit bandwidth indicates the maximum and mean network egress speeds for each activation server. This might be helpful information to monitor whether jobs are network-bound via the transmission speeds of a lagging node.
The following figure shows that most weight servers achieve a network transmit speed of ~420 MB/s:
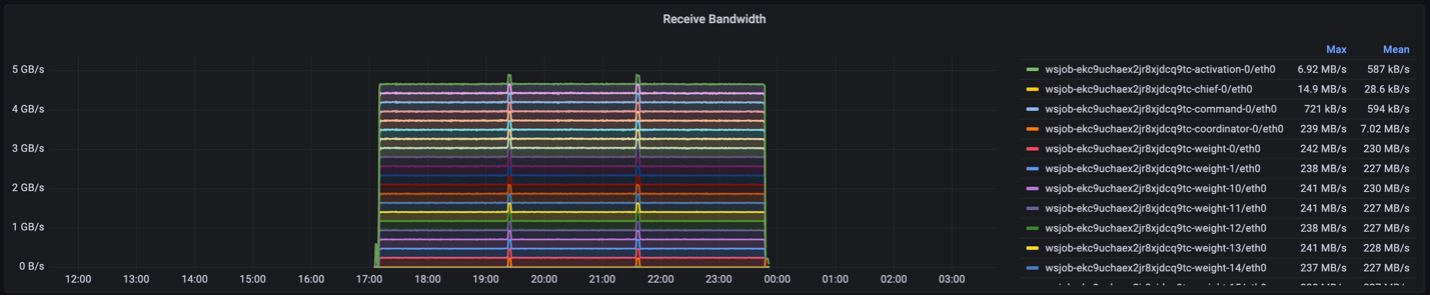
2. Receive bandwidth denotes the ingress speeds for each supporting server. For example, in this instance, the weight servers have an average ingress speed of around 220MB/s.
The following figure shows the receive bandwidth metric:
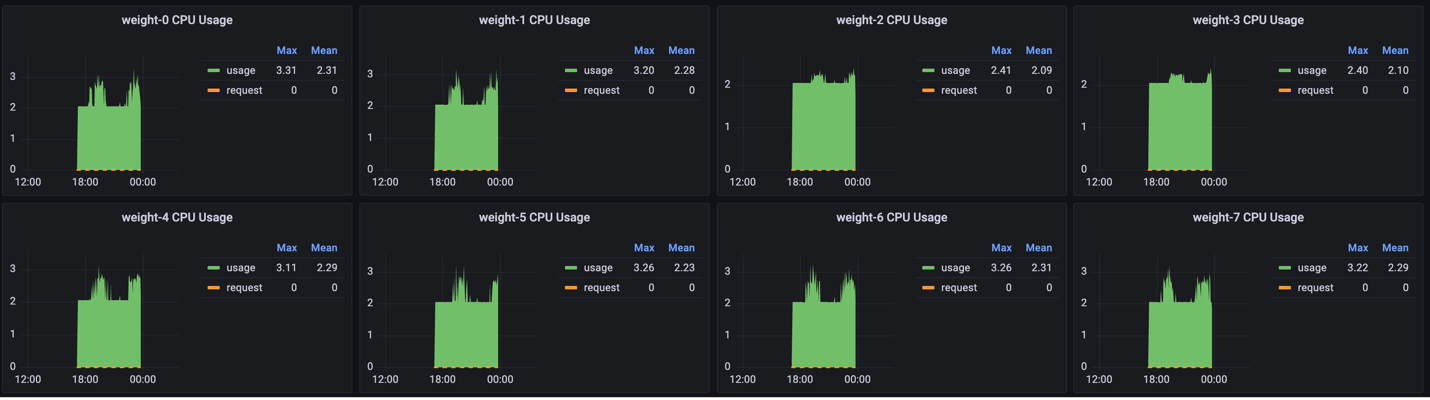
3. CPU usage shows the CPU percentage utilization for each weight-server. In this case, the CPUs are only 2-3% utilized.
The following figure shows the cpu usage metric:

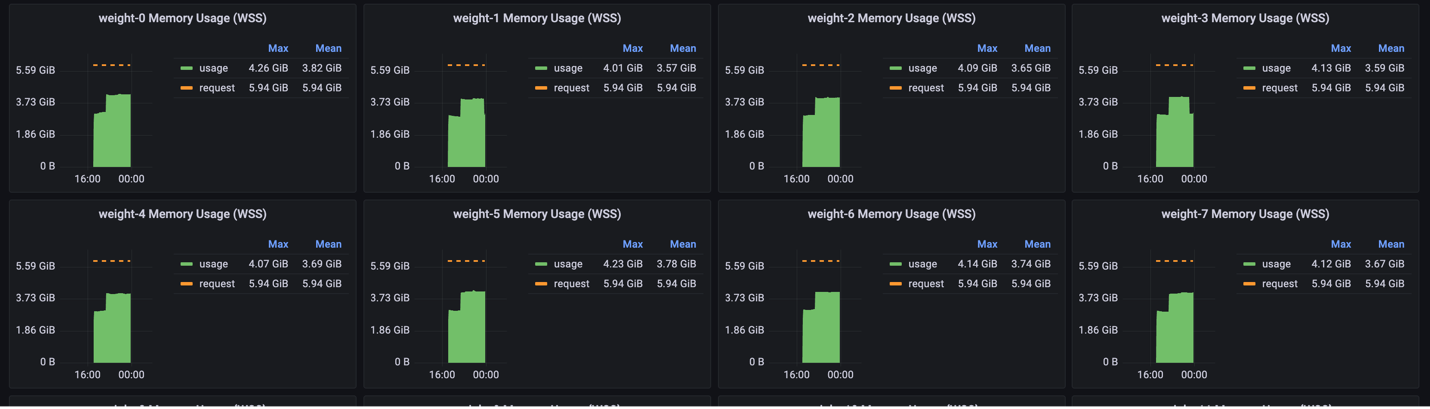
4. Memory usage indicates the maximum and mean amounts of memory each weight server uses over time. This can be useful in debugging whether the weight servers are memory bound. For more information on memory requirements, visit Resource requirements for parallel training and compilation.
The following figure shows the memory usage metric:

5. You can use the Grafana interface to show individual metrics for each node. For example, these are the views for CPU and memory usage per node:
The following figure shows the cpu usage per node metric:
The following figure shows the memory usage per node metric: