Train a model with weight sparsity#
Overview#
In 2018, state-of-the-art neural networks such as BERT had a few hundred million parameters. Two years later, the world was introduced to GPT-3. With 175 billion parameters and a 3.14*1023 FLOPs (floating point operations) compute budget, it is estimated to have required 10,000 NVIDIA V100 GPUs for 15 days, accounting for 552 tons of CO2e emissions and 1,287 MWh of energy [Patterson et al.].
Evidently, training large models is costly. With parameter counts and datasets getting larger and larger every year, new approaches are needed to reduce the time, energy, and carbon footprint required to train. Weight sparsity, coupled with hardware that accelerates it, is a promising way to train models using significantly less compute and memory.
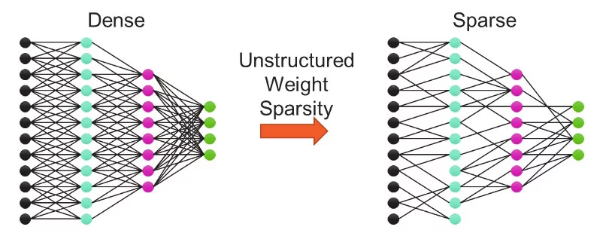
Weight sparse training methods set subsets of weights to zero. The resulting sparse model requires far fewer FLOPs to train and fewer parameters to store, as multiplies with zeros get skipped on both forward and backward passes through the network. Only systems that can accelerate sparsity, such as Cerebras CS-X and CS-3, can take advantage of the lower resource requirement and use the reduction in FLOPs to significantly accelerate training. Finding and training sparse models to match the accuracy of their original “dense” (i.e., non-sparse) configurations is an active and open area of research!
Sparsity via YAML#
When using the Cerebras Model Zoo reference models, runs are parameterized via
YAML configs that include model, data, and optimizer parameters (GPT-3 example
here). To
train with sparsity, you can include a sparsity section in your run’s YAML
config file as a sibling to the model and optimizer sections. Each
parameter is sparsified independently. i.e. we don’t yet support global
sparsity.
For example, with the following config, the sparsity level is set to 0.3 (30%),
and init_method is "random", which means 30% of the elements in each
Parameter (which passes the default parameter filter) will be pruned once at model initialization and kept
that way throughout training. Non-Parameter tensors are not pruned.
sparsity:
algorithm: "static"
sparsity: 0.3
init_method: "random"
Sparsity is parameterized primarily by the following keys:
algorithm:Sparsity training algorithm to apply.
Static(Default): Fixed sparsity level throughout trainingGMP: Gradual magnitude pruningSET: Sparse Evolutionary TrainingRigL: Rigging the Lottery
You can also define a custom class that inherits from
SparsityAlgorithm. As long as the class in the global scope, i.e. by importing it in yourrun.py, it can be directly used in a YAML config, e.g.class CustomSparsity(cstorch.sparse.SparsityAlgorithm): ...
sparsity: algorithm: CustomSparsity ...
See Writing a Custom Sparsity Algorithm for more details on how to write a custom sparsity algorithm.
sparsity:The desired sparsity level between 0 and 1. 0.0 means the Parameter is kept fully dense. 1.0 means the Parameter is effectively entirely zeros. Dynamic sparsity algorithms also accept more complex configuration described below in Dynamic Hyperparameters.
Note
The actual sparsity level may not match the target sparsity level in practice. The target sparsity level only represents a target distribution. The true sparsity level is determined by the size of the Parameter that is being sparsified.
For example, if you were to sparsify a Parameter with shape (5,) targeting a sparsity level of 0.5, the actual sparsity level will only ever be 0.4. The smaller the Parameter, the more extreme this discrepancy becomes. If the Parameter is a scalar tensor, then the actual sparsity level will always either be 0.0 or 1.0.
init_methodoptional:Method to compute the initial sparsity distribution.
random: (default) Sparsity is randomly distributed within each weight.topk: Sparsity is distributed according to the lowest magnitude weights.from_zeros: Sparsity pattern is determined by weight values that are already zero.
param_filteroptional:Controls which Parameters are sparsified. The list of Parameter names can be found using
model.named_parameters().When this is omitted, any multidimensional Parameters (except those with
embedding,norm, orlm_headin their name) automatically get sparsity applied (single dimensional weights such as biases are ignored) (Seedefault_sparse_param_filter).While this provides a good default heuristic for transformer based models 1, a (list of) glob expressions can also be provided to only apply sparsity to Parameters which match, e.g.
param_filter: - "*dense_layer.weight" - "*linear_layer.weight"
To match all weights, set
param_filter: *Per-layer sparsity options can be configured by passing in a list of configuration dictionaries. See below in advanced param_filters.
Dynamic Sparsity Update Schedule#
Dynamic sparsity (e.g. GMP,
SET, or
RigL) needs an
additional update schedule indicating when to update the sparsity pattern.
There are 2 basic methods built-in with 3 different options:
Regular Interval#
When sparsity should be updated at a regular interval, a single frequency can be given:
sparsity:
update:
freq: 100
algorithm: set
sparsity: 0.9
Here, sparsity will be initialized at 90% and steps 0,…,99 will be performed with a fixed sparsity pattern. Every 100 steps, the sparsity pattern will be updated according to the SET algorithm.
To control beginning and ending steps, use a dictionary. In the following example, sparsity will be initialized at 0% and steps 0,…,76 will be performed without sparsity. Starting from step 77 and every 100 steps until step 377, the sparsity pattern will be updated according to the SET algorithm. After step 377, the sparsity pattern will continue to be applied, but it will no longer be updated (stop is exclusive).
sparsity:
update:
start: 77
freq: 100
stop: 477 # An update will _not_ be performed on step 477
algorithm: set
sparsity: 0.9
Irregular Interval#
When sparsity should be updated at arbitrary steps, specify them in a list:
sparsity:
update:
steps: [0, 5, 20, 50]
algorithm: set
sparsity: 0.9
Dynamic Hyperparameters#
Dynamic sparsity algorithms (e.g. GMP,
SET, or
RigL) can configure the sparsity (and
drop_fraction for SET and
RigL) field using a “step aware
hyperparemeter” akin to learning rate schedules in addition to simple constants.
These more complex configurations usually require additional options and so are
specified as dictionaries.
Note
The base
DynamicSparsityAlgorithm that
invokes such a dynamic hyperparameter for sparsity ensures sparsity
levels stay legal by using torch.clamp(sparsity, min=0.0, max=1.0).
Linear#
\(y(step) = init + slope \cdot step\)
sparsity:
algorithm: "gmp"
update:
freq: 1000
schedule:
type: "linear"
init: 0.0 # value at step zero
slope: 0.001 # increase in value each step
Exponential#
\(y(step) = final + (init-final) e^{step \cdot gamma}\)
This is expecially useful for GMP, where
the sparsity level monotonically increases throughout training because a
fraction of the remaining elements in the Parameter are pruned at each update
step, asymptotically approaching an empty network.
sparsity:
algorithm: "gmp"
update:
freq: 1000
schedule:
type: "exp"
init: 0.0 # starting value
final: 1.0 # asymptotic ending value
# Prune 10% of the remaining connections every 1000 steps
gamma: -0.00010536051 # ln(1-0.10)/1000
Cosine#
\(y(step) = o + a \cdot \cos(step \cdot \pi / half\_period)\), where \(o = (init + minimum)/2\) and \(a = init - o\).
This is especially useful for RigL, which
usually uses a “cosine decay” on its drop_fraction. minimum defaults to
0.0. half_period controls what step the value reaches its minimum.
sparsity:
algorithm: "rigl"
update:
freq: 1000
sparsity: 0.9
drop_fraction:
type: "cosine"
init: 0.3 # starting value
half_period: 10000 # reaches minimum (default 0) after 10 updates
More Config examples#
The most basic configuration, applying random 30% sparsity to all Parameters:
sparsity:
sparsity: 0.3
Apply uniform (static) sparsity to a selected set of weights, with a sparsity pattern guided by the weight magnitudes:
sparsity:
sparsity: 0.9
init_method: "topk"
param_filter:
- "dense_layer.weight"
- "linear_layer.weight"
Basic dynamic sparsity using the SET algorithm. Update the sparsity pattern every 1000 iterations.
sparsity:
algorithm: "set"
sparsity: 0.9
update:
freq: 1000
drop_fraction: 0.3
Configuring Multiple Sparsity Algorithms#
Different groups of Parameters can be sparsified using different sparsity algorithms.
For example, if one set of weights should be statically sparsified to say 0.3,
but another set of weights should be dynamically sparsified using the SET algorithm,
it can be done by providing a list of sparsity algorithms.
sparsity:
- param_filter: "fc1.*"
sparsity: 0.3
- param_filter: "fc2.*"
algorithm: "set"
sparsity: 0.9
update:
freq: 1000
drop_fraction: 0.3
Advanced param_filters#
When each Parameter (or group of Parameters) needs different configuration,
param_filters can be specified as a dictionary, mapping “patterns” to
the config dictionaries to overlay on the default sparsity config options.
For example, when using RigL on transformer networks (uses gradient information to guide which values in a Parameter to prune), sparsity can be cyclically restributed between the heads of attention projection weights in case samples in a batch activate one head disproportionately to another. This ultimately decreases the effectiveness of dynamic sparsity and even can hurt model performance.
To ensure sparsity is fairly distributed between the different attention heads
of the multi-head attention projections, you can specify balance_out_groups
when the output logits are logically N independent/stacked groups (i.e. input
projection weights before multi-head attention QKV), or balance_in_groups
for the reverse (i.e. output projection weights). These should apply differently
to different weights using param_filter since this conceptually only applies
to Attention projection weights. In the following example, the model has 12
attention heads.
rigl_config: &rigl-config
algorithm: "rigl"
sparsity: 0.9
update:
freq: 1000
drop_fraction:
type: "cosine"
init: 0.3
half_period: 10000
sparsity:
- <<: *rigl-config
param_filter: "*proj_[qkv]_dense_layer.weight":
balance_out_groups : 12 # ensure this matches model.num_heads
- <<: *rigl-config
param_filter: "*linear_layer.weight":
Running a Sparse Model#
No change is needed to the run command (see guide: Launch your job) -
ensure the .yaml file has sparsity enabled. To validate your sparsity
config before launching training, run with --validate_only. You can also
log which weights are being sparsified by passing --logging VERBOSE to your
run command.
python modelzoo/path/model/run.py CSX \
--params params_with_sparsity.yaml \
--num_csx=1 \
--model_dir model_dir --mode {train,eval,eval_all,train_and_eval} \
--mount_dirs {paths modelzoo and to data} \
--python_paths {paths to modelzoo and other python code if used}
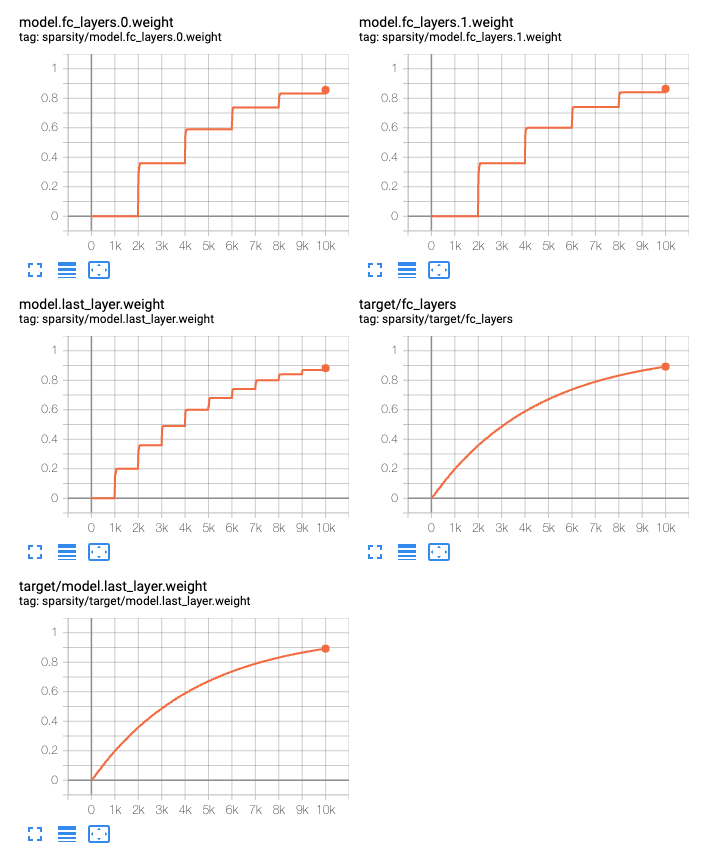
When using dynamic sparsity, you can see realtime summaries by setting the
config field add_summaries: True. Each group of Parameters independently
summarizes its target sparsity as well as the actual computed sparsity of each
tensor.
gmp_config: &gmp-config
# Enable tensorboard summaries for target and actual sparsity
add_summaries: True
algorithm: "gmp"
schedule:
type: "exp"
init: 0.0 # starting value
final: 1.0 # asymptote value
# Prune 20% of the remaining connections every 1000 steps:
gamma: -0.0002231435513142097 # ln(1-0.20)/1000
sparsity:
- <<: *gmp-config
param_filter: ".*fc_layers.*weight":
update:
freq: 2000
- <<: *gmp-config
param_filter: ".*last_layer.*weight":
update:
freq: 1000
Sparsity via API#
Please see Sparsifying models for more details on how to configure sparsity using the Cerebras PyTorch API.
Related research#
Sparsity is a powerful tool that can improve performance, reduce the model size, and help generalizability while achieving the same accuracy as densely trained models. Read some of our research work on training with sparsity here:
Sparse pre-training and dense fine-tuning (SPDF): blog, arxiv, PMLR. This work shows how we can pre-train a 1.3B parameter GPT-3 style model with up to 75% unstructured sparsity and 60% fewer training FLOPs on Cerebras CS-X, without significantly losing accuracy on downstream tasks.

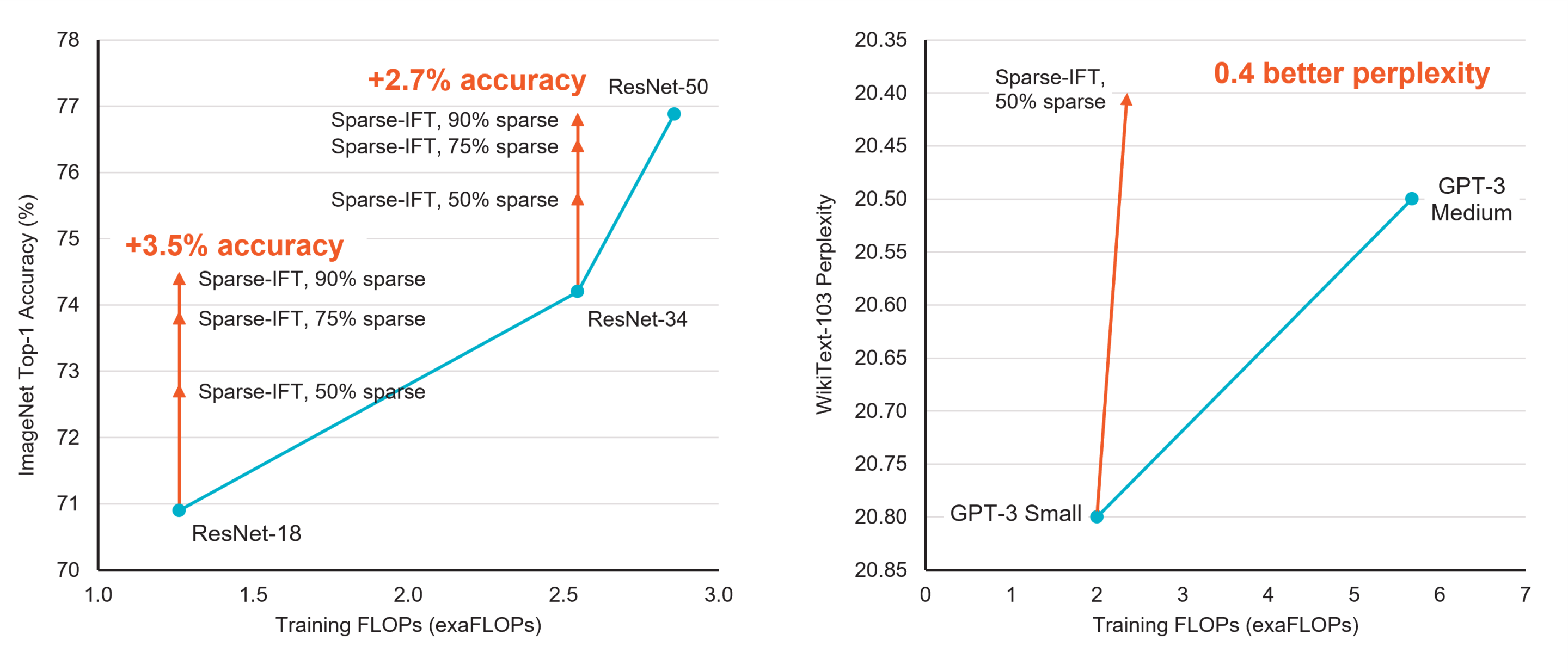
Sparse Iso-FLOP transformations for Maximizing Training Efficiency (Sparse-IFT): blog, arxiv. This work shows how pre-training a GPT-3 style small model with sparsity leads to a 0.4 perplexity improvement on the WikiText103 language modeling task. See the table below and paper for more details, including results on computer vision tasks.
Variable Sparse pre-training and dense fine-tuning (Variable SPDF): blog. This work extends SPDF, demonstrating the scaling up to a 6.7B GPT-3 style model with a 64% FLOPs reduction while maintaining downstream model performance. This is accomplished by performing the majority of pre-training at static sparsity, then finishing pre-training on a dense version of the model before fine-tuning on the dense version as well.

Footnotes
- 1
Sparsity on CSX has not yet been thoroughly validated with convolutional networks.