Sharding For the CS system
On This Page
Sharding For the CS system¶
When multi-worker nodes are deployed to provide input data to the CS system for training, you can present the input data either by:
Copying the entire dataset onto each worker’s memory, or
Shard the dataset into smaller, distinct slices so that each worker presents only a slice, or a shard, of the dataset. This is a recommended option when your dataset is very large or the available local memory on your CPU nodes is limited.
See more in Multi-Worker Input Pipeline.
When sharding the input dataset for the training on the CS system, there are two approaches, depending on the location and state of the input data. Cerebras provides example Python scripts for these approaches. See the following:
When the input data is in TensorFlow tf.data.Dataset objects, then use the
shard_dataset.pyutility. Theshard_dataset.pyutility is specifically designed for using data in TensorFlowTFRecordDatasetor other inbuilt dataset mechanisms such asFixedLengthRecorddatasets orTextLineDataset.
Based on the number of available workers (in case of the CS system) or GPUs (in case of multi-GPU), this utility splits the dataset across the workers or GPUs. The end result is that each worker streams a different subset of the input data to the CS system.
- When the input data is very large and is located on a data store, then use the pair of utilities, split_utils.py and subset_utils.py to shard the data.
Important
Commonly you would use only one of the two approaches described in this section.
Data in tf.data.Dataset¶
When your dataset is already in the form of TensorFlow objects of the type tf.data.Dataset, or for example, FixedLengthRecord or TextLineDataset, then these objects are already in memory. In this case, use the shard_dataset.py utility to shard this dataset.
Important
When using the CS system for training, we recommend using the shard_dataset.py utility instead of the shard method of TensorFlow to shard the input data. The shard_dataset.py utility uses a CS system-aware mechanism to retrieve the number of workers and worker IDs.
See below the Python code for shard_dataset.py utility.
Script¶
import os
import json
def shard_dataset(dataset, use_multiple_workers, input_context=None):
# Multi-gpu input context, using only multiple GPUs and not the CS system
if not use_multiple_workers and input_context:
num_workers = input_context.num_input_pipelines
worker_id = input_context.input_pipeline_id
dataset = dataset.shard(num_workers, worker_id)
# Multi-worker context for the CS system data loading
# in this case no input context should be generated
elif use_multiple_workers:
cond = True
# Since all workers do not instantiate at the same time,
# we wait till the TF_CONFIG is populated and then proceed
# with sharding of the dataset
while cond:
if 'TF_CONFIG' in os.environ.keys():
cond = False
config = json.loads(os.environ['TF_CONFIG'])
num_workers = len(config['cluster']['worker'])
worker_id = config['task']['index']
dataset = dataset.shard(num_workers, worker_id)
return dataset
Description¶
The shard_dataset.py utility shards a dataset based on whether you are using a multi-GPU setting or using a CS system with multiple workers.
Note
For single worker configuration on the CS system, it is recommended to pass use_multiple_workers as False.
dataset: Input. Of the datatypetf.data.Dataset. The TensorFlow dataset to shard.use_multiple_workers: Input. Of the datatypebool. Specifies whether multiple workers are used with the CS system or not.input_context: Input. Of the datatypedict. Given by the distributed strategy for training.Returns
dataset: Returns the sharded dataset if eitherinput_contextoruse_multiple_workersis passed, else returns just the dataset.
Data in files¶
When your very large input data is physically located somewhere on the network, such as on a network-attached storage, then the following preprocessing of the data should be performed before queueing the input data for CS system:
Split the input files into a specified number of shards.
Create subsets and corresponding metadata files from all the shards.
Copy the data to corresponding workers (manual process for now).
Scripts¶
Cerebras provides the following Python scripts to shard the data and to create subsets.
split_utils.py: To shard the source data that is in CSV format.subset_utils.py: To create subsets from the shards.
Example¶
The following diagram depicts a high level view of how to create shards and subsets using the scripts split_utils.py and subset_utils.py.
The example considers a “large” input dataset for training, consisting of 100 rows, represented in a CSV format. It then creates 10 shards from this input dataset. The number of workers are configured to be 5. A subset consisting of two shards is created for each worker. A subset is formed by randomly selecting two shards, making sure that any shard is selected to be in only one subset. Each such subset is then provided to a worker.
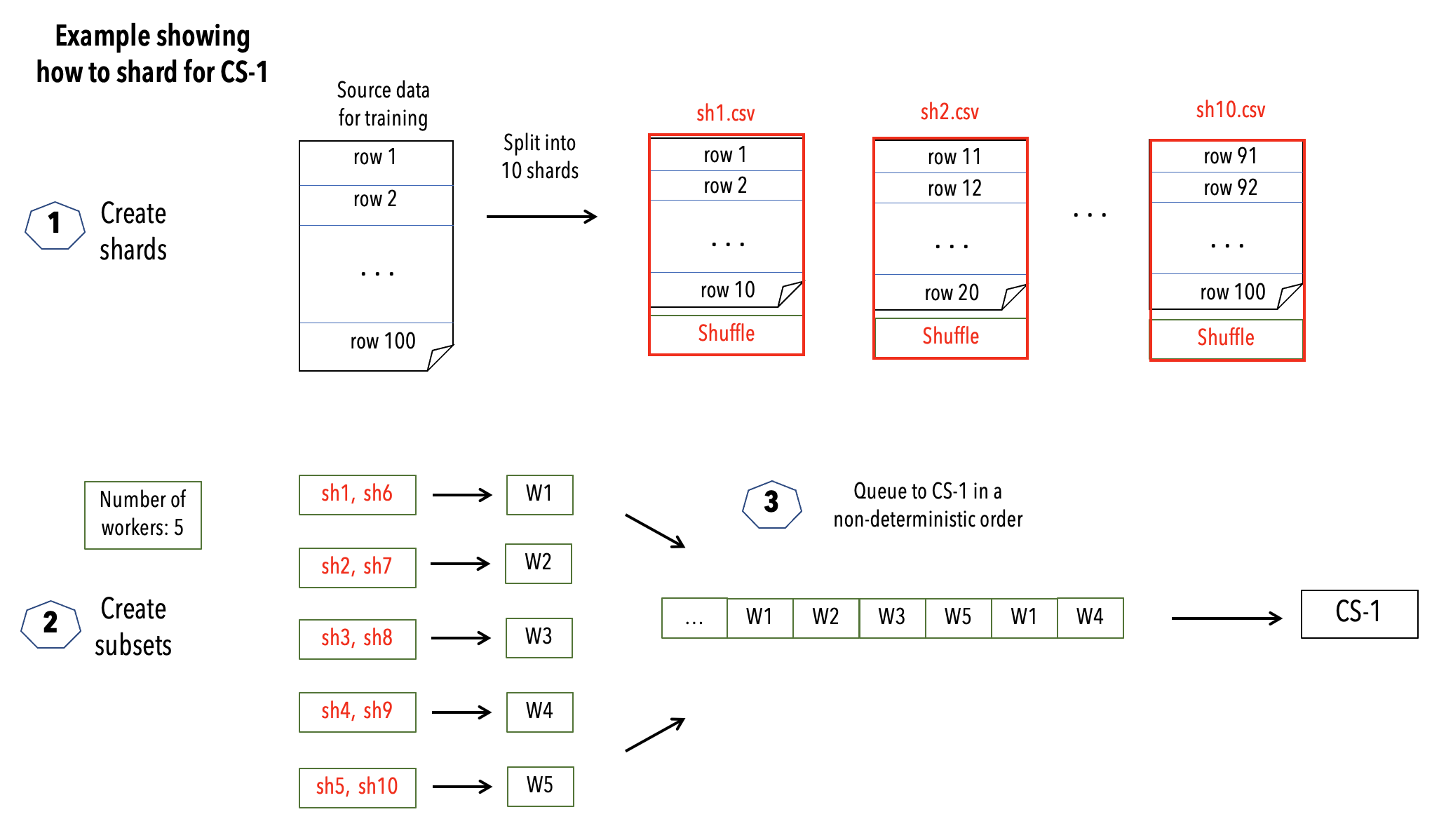
Fig. 3 Sharding input data for CS system¶
Creating shards¶
Process a single file¶
To shard a single CSV file, execute the following command:
python split_utils.py --input_files </path/to/input/file> \
--output_folders </path/to/output/folder> \
--num_splts <(int)> --line_counts <(int)> \
--num_lines_read_chunk <(int)>
where:
input_files: Path to the input CSV file that should be split.output_folders: Path to the folder in which the split files are placed. Each output file is of the forminput_file_{n}.csv, wherenis the number of splits,num_splits.num_splits: Integer. The input file will be split into this number of files. Defaults to 100.line_counts: Number of lines in the input file. For very large files computing this parameter takes a long time, hence we recommend that you provide this value. If not provided, it is computed during the execution.num_lines_read_chunk: Number of lines to read into memory at a given instant. This number can be increased or decreased, depending on the compute capability. Defaults to 10000.
Process multiple files¶
To shard N files in parallel, execute the following command by providing a list of comma-separated arguments for each parameter:
python split_utils.py --input_files file1.csv,file2.csv,...,fileN.csv \
--output_folders output1,output2,...,outputN \
--num_splits split1,split2,...,splitN \
--line_counts count1,count2,...,countN \
--num_lines_read_chunk lines1,lines2,...,linesN
where:
input_files: A comma-separated list of N CSV files to split simultaneously.output_folders: Path to the folder in which the split files are placed. Each output file is of the forminput_file_{n}.csv, wherenis the number of splits,num_splits.num_splits: Integer. The input file will be split into this number of files. Defaults to 100.line_counts: Number of lines in the input file. For very large files computing this parameter takes a long time, hence we recommend that you provide this value. If not provided, it is computed during the execution.num_lines_read_chunk: Number of lines to read into memory at a given instant. This number can be increased or decreased, depending on the compute capability. Defaults to 10000.
Tip
You can pass single values for num_splits and num_lines_read_chunk even when processing multiple files. The code will automatically apply this unique value for all the input files.
Note
Check the code for the utility for additional information on each parameter.
If for a given file, the
line_countsparameter is not exactly divisible bysplits, then the remaining data is appended to the final file. This may result in a larger size for the final file.The code uses the multiprocessing library and asynchronous calls to process multiple files and write the outputs. We recommend you spin up a compute server that can handle the necessary I/O, compute and memory loads, based on the file sizes.
Generating subsets¶
Groups of shards, formed by randomly sampling the above-created shards, are called subsets. Any two subsets contain mutually exclusive shards. These subsets are then copied to a worker. The number of workers should be known prior to generating the subsets.
The subset_utils.py first randomizes the order of the sharded CSV files, and then selects successive CSV files to allocate them to a subset.
The following shows how to use subset_utils.py command to generate the subset files for a given number of workers, such that the data is split across these workers evenly:
python subset_utils.py --input_folder </path/to/input/folder/> \
--output_folder </path/to/output/folder> \
--num_workers <(int)> \
--check_validity
where:
input_folder: Folder containing the split files when the shards are created. It should be the same asoutput_foldersfrom the above creating shards step.output_folder: Folder to which this subset creation script writes the subsets for workers. This folder will containnum_workerfolders, each containing the data to copied to a particular CS system worker node, and the corresponding metadata file.num_workers: Integer. Number of workers.check_validity:The script runs a validity check to ensure the mutual exclusivity in subsets. Defaults toFalse.
Comparison¶
See the following table for a quick comparison between the two sharding approaches described in this section.
Data in Files |
Data in TensorFlow tf.data.Dataset |
|
|---|---|---|
Recommended Cerebras Utilities |
|
|
Input Worker Node(s) |
De-centralized worker |
Centralized worker |
Data Location |
Data store |
In memory |
Input Data Formats |
Text (compressed files with variable-length data). |
TensorFlow tf.data.Dataset (compressed files with fixed-length data). |
Hardware |
CS system |
CS system and GPU |
Software |
DL Library-independent |
TensorFlow-specific |