Sparsity
On This Page
Sparsity¶
In 2018, state-of-the-art neural networks such as BERT had a few hundred million parameters. Then just two years later, the famous GPT-3 model had 175 billion parameters. That represents over 1000x growth in compute demand in just two years. The GPT-3 model, for example, famously took months and millions of dollars to train on 1,024 GPUs, for a single training run. There is no end in sight for this growth as the ML community continues to demonstrate larger models continue to improve accuracy. Soon we will be striving to run models with trillions of parameters.

The compute and memory requirements are already prohibitive even for the largest companies in the world. We need a better way to grow models more efficiently, to get the advantages of larger models but with substantially less compute and memory resources.
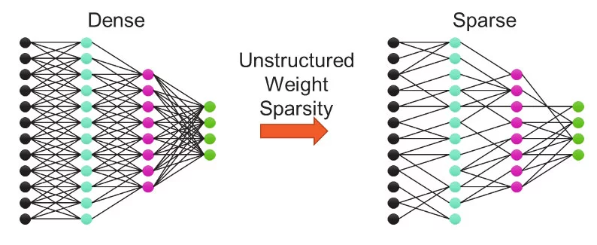
Neural network models are made up of layers of neurons and connections between them. The number of layers, the number of neurons per layer, and the pattern of connections together make up the structure of the model. The connections are represented as weights in a collection of matrices, one for each layer of the model. When there are missing connections, represented as zeros in the weight matrices, we refer to the model as sparse. For all zero weights, no computation or memory is required during training or inference to achieve the correct result. However, only hardware that can accelerate sparsity, such as Cerebras CS-2, can take advantage of the lower resource requirement.
Implementation Detail¶
In our CS-2, for those weights we want to sparsify we set the value as NaN. NaNs will not be involved in computation, as a result, the sparsified model can be trained faster. At the end of the training, a sparsified checkpoint will be saved. Again, the checkpoint will have NaNs in it.
The sparsification function will be applied on each layer. In other words, If the sparsity level is set as 0.5 (50%), then parameters in each qualified layer will have 50% NaN value.
Config Snippet Demonstration¶
With our sparsity options, you can create your own sparsity config file based on other models. Below are some code snippet examples. Our sparsity config .yaml for gpt2-small can be found here.
Currently, we support random and topk sparsity methods. For random sparsity, the indices of the sparsity parameter tensor are selected randomly based on given random seed. For topK sparsity, the indices of the sparsity parameter tensor are selected based on magnitude of tensor value. The default setting is topk.
sparsity:
type: sideband
sparsity: 0.3 # uniform sparsify of every >1D non-norm non-embedding tensor (default heuristic)
init_method: "random"
seed: 1234 # random sparsity pattern is deterministic based on parameter name, but a different sample can be obtained via seeding
Set ``param_name_patterns`` to sparsify specific parameters.
sparsity:
type: sideband
sparsity: 0.3
init_method: "random"
param_name_patterns: "fc_layers.*weight" # only these tensors, regex supported
seed: 1234
sparsity:
type: sideband
sparsity: 0.3
init_method: "topk" # absolute weight magnitude based sparsity; also the default setting of `init_method`
param_name_patterns: # only these tensors, multi regex supported
- "fc_layers.*weight"
- "final_layer.*weight"
Apply different sparsity levels to different parameters.
sparsity:
type: sideband
param_name_patterns:
fc_layers.*weight: # per-tensor-group setting (can set init_method, sparsity, seed, etc per group)
sparsity: 0.3
final_layer.*weight:
sparsity: 0.4
How to Run¶
The run command keeps the same as other runs.
python run.py --mode train --params /path/to/yaml --model_dir /path/to/model_dir
Note that the .yaml provided should have sparsity enabled.
Results¶
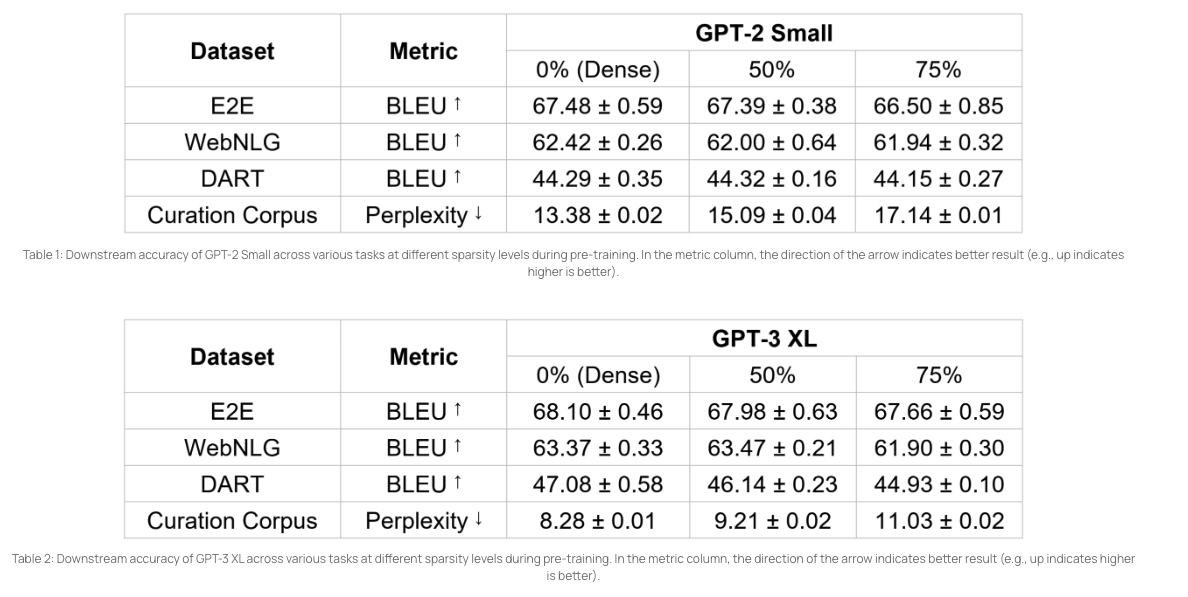
Currently, we show how pre-training GPT models can be accelerated by the Cerebras CS-2, with its support for unstructured weight sparsity, to reduce the training FLOPs (floating point operations) by up to 2.5x, while retaining the benefits of pre-trained textual representations in large language models. For more information about the work detail, see Accelerating Large GPT Training with Sparse Pre-Training and Dense Fine-Tuning.